Erlang Liveness Checks in Kubernetes
Tue, Jun 12, 2018I have an ever-increasing number of small projects and deployments that I use either internally or with some availability to the public, and have been relying on Kubernetes to make managing them easy. Not too long ago, I started adding a liveness probe to each pod definition as a contingency against a hung runtime. My pod definition at the time looked like this example from my Aflame project:
containers:
- name: aflame
image: docker-registry:5000/erlang-aflame
livenessProbe:
exec:
command:
- /deploy/bin/aflame
- ping
initialDelaySeconds: 5This worked fine, and I was able to verify that nodes that failed the ping test would be taken down. However, some weeks later I was poking around and realized that CPU utilization on my server was significantly higher than I would expect.
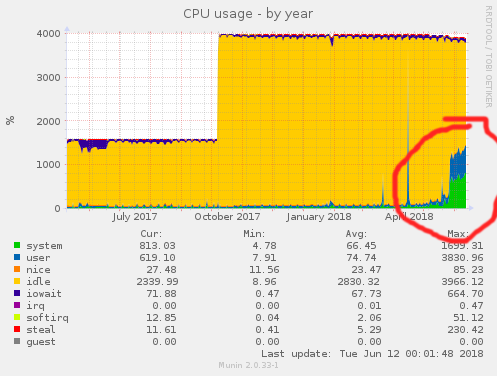
Note the recent spike in CPU utilization
Looking at htop, it was difficult to see a precise culprit, except for
a large number of processes called erl_child_setup coming into
existence, pegging a CPU core and disappearing again. After googling around, I
landed on the
source code
for this task and found this section of main:
/* We close all fds except the uds from beam.
All other fds from now on will have the
CLOEXEC flags set on them. This means that we
only have to close a very limited number of fds
after we fork before the exec. */
#if defined(HAVE_CLOSEFROM)
closefrom(4);
#else
for (i = 4; i < max_files; i++)
#if defined(__ANDROID__)
if (i != system_properties_fd())
#endif
(void) close(i);
#endifAccording to the ps output on my system, max_files was getting set to
1,048,576 - so every time this program run, it was hot looping over a million
possible file descriptors and calling close on each! No wonder it was
resulting in so much system time. But what was actually causing all of these
erl_child_setup calls? I had initially suspected a misbehaving deployment
code, but the spike in load lined up with when I added the liveness checks. It
turns out that the relx ping command is surprisingly heavyweight; or at
least ends up that way when run in an environment with a very high max file
count, which was the case under docker.
The fix
In order to fix this, I altered my liveness probe to run the ping check with a
low ulimit on the number of open files. We still need to loop, but we are at
least looping over a considerably more restrained number of descriptors.
I also took the
opportunity to increase the interval between checks, since the default check
period is rather quick.
containers:
- name: aflame
image: docker-registry:5000/erlang-aflame
livenessProbe:
exec:
command:
+ - softlimit
+ - -o
+ - "128"
- /deploy/bin/aflame
- ping
initialDelaySeconds: 5
+ periodSeconds: 60
Note that in order to get softlimit in your container, you may need to
rebuild with daemontools package installed, or another source that contains
a limit utility.
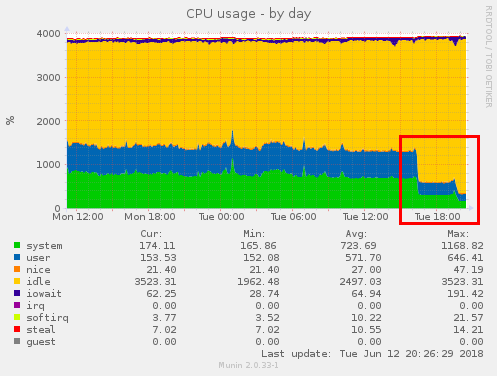
Noticably reduced CPU usage
With these changes, system load rapidly dropped from nearly 20 to a more
reasonable 3. The default performance of this wrapper would likely be helped by
an adoption of the closefrom syscall into the Linux kernel, but unfortunately
the only references I can find to this are
a pessimistic ticket from 2009
and an unmerged
patch from Zheng Liu in 2014.